Difference between revisions of "ASCII"
| Line 358: | Line 358: | ||
[[Category:Web Development]] | [[Category:Web Development]] | ||
| + | |||
| + | <html><script type="application/ld+json"> | ||
| + | { | ||
| + | "@context": "https://schema.org/", | ||
| + | "@type": "ImageObject", | ||
| + | "contentUrl": "https://www.seobility.net/en/wiki/images/f/f8/ASCII.png", | ||
| + | "license": "https://creativecommons.org/licenses/by-sa/4.0/", | ||
| + | "acquireLicensePage": "https://www.seobility.net/en/wiki/Creative_Commons_License_BY-SA_4.0" | ||
| + | } | ||
| + | </script></html> | ||
Revision as of 10:08, 23 September 2020
Contents
Definition
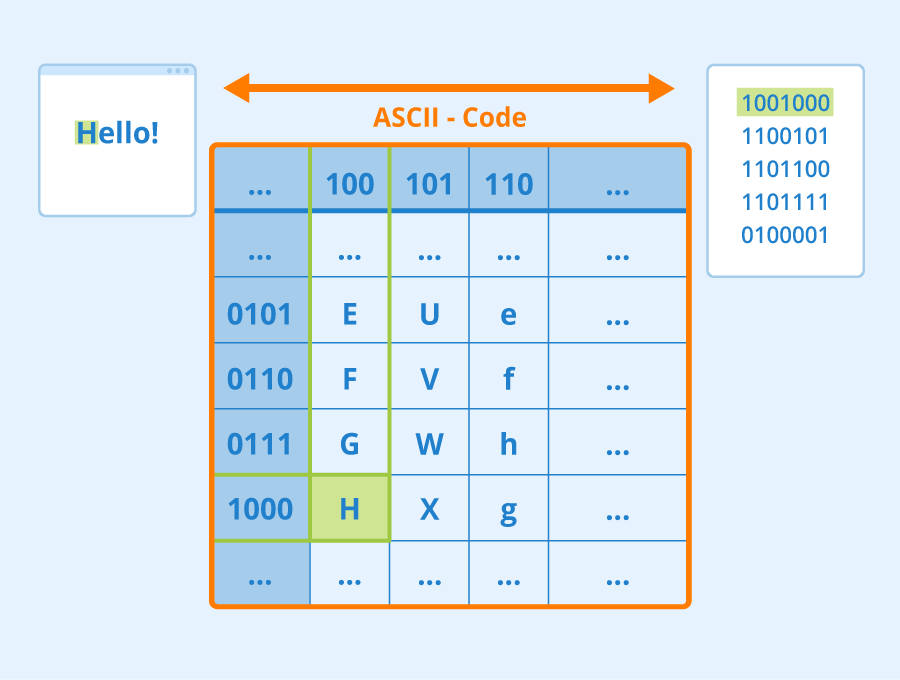
The term ASCII stands for "American Standard Code for Information Interchange" and describes a character set standard for text data and information exchange. Character encodings (also called code pages) define how letters and other text characters, as well as control codes for data transfer, are to be encoded in bits and bytes.
The ASCII-code is one of the most important character set standards along with Unicode, ISO-8859-1 and Windows 1252. The code was the dominant standard for web pages for a long time until it was overtaken by the Unicode encoding UTF-8 in 2007. Nevertheless, it is still relevant today, as there are still areas where only characters contained in the ASCII code are allowed.
History
ASCII code has a long history. This history began with telegraphy and Morse code as well as the 5-bit Murray code developed by the New Zealand inventor Donald Murray between 1901 and 1932. The first version of the ASCII code was released in 1963 by ASA, the American Standards Association. ASA was a precursor of the American National Standards Institute (ANSI). In 1968, the version of the character set that is still valid today was published.
The 7-bit ASCII character set
Because of its history, the original ASCII code uses only seven bits of a common 8-bit byte and can encode a maximum of 128 different characters. The code contains upper and lower case letters of the English alphabet, the most important punctuation marks, mathematical symbols, and 33 control codes for data transfer and text formatting.
The following character groups are included:
- 0-32 and 127: control codes for data transfer as well as spaces, tabs, and line breaks
- 48-57: digits
- 65-90: capital letters
- 97-122: lower case letters
- 33- 7, 58-64, 91-96 and 123-126: punctuation marks, mathematical symbols, brackets, and other characters
Country-specific special characters such as umlauts and accents are not included in ASCII code.
Although the arrangement may seem chaotic and arbitrary, it results from thorough planning and consideration. The letters are positioned in such a way that upper and lower case versions of a letter only differ by a single bit. Numbers, spaces, and some other symbols are deliberately placed in front of the letters to simplify sorting. In addition, many non-alphanumeric symbols are located on positions similar to typewriter arrangements.
Extended character sets: ISO-8859
Since the actual ASCII code only contains the English alphabet, many region-specific extensions have been developed. In this context, the character sets Windows-1252 and ISO-8859-1 have gained particular importance. Both are 8-bit extensions of the original standard and contain many special regional characters. Due to historical developments, both standards are often referred to as ANSI character sets. Strictly speaking, however, this is not correct because ANSI has never officially standardized these character sets.
However, even with 8 bits, only 256 characters are available and therefore not all languages can be covered. Therefore, ISO-8859 has been developed as a collection of different character sets for different languages and regions. For example, ISO-8859-7 contains Latin and Greek alphabets, while ISO-8859-4 covers the special characters of Scandinavian and Baltic languages. ISO-8859-1 contains Western European alphabets and is almost identical to Windows 1252.
For both Windows 1252 and ISO 8859-1, the first 128 characters are identical to ASCII code. From position 128, code-specific special characters follow, whereby the numbers 128 to 159 are undefined in the ISO-8859 standard. Starting with number 160, the special characters of the different languages and regions are contained.
ASCII, Unicode, and UTF-8
Although the ISO-8859 standards cover many languages, not all languages are included. In addition, the different character sets caused a considerable amount of confusion because they are not compatible with each other. As early as 1988, the first plans for a uniform Unicode character set were drawn up, the first version of which was released in 1991.
Unicode enables the display of over a million characters and gradually replaces all other character sets. The Unicode encoding UTF-8, which now is the predominant text format on the World Wide Web, is particularly important. UTF-8 has the big advantage that it is ASCII compatible since the first 128 characters are identical.
Structure of ASCII and ISO tables
Usually, lists or tables are used to display the character sets in order to make the characters and their numerical values easy to find. These lists specify the characters and their decimal, hexadecimal, octal, and/or binary values.
Many tables are hexadecimal and separate the codes into the first and second half bytes. For example, the large H in the ASCII table is found in the 4th row of the 8th column, resulting in the hexadecimal notation 0x48. The carriage return CR has the code 0x0D because it is in line 0 and column D. 0x is a common prefix to refer to the hexadecimal notation.
ASCII Table
In the following, you can see the ASCII table with codes in decimal, hexadecimal and octal notation:
|
|
|
| char. | decimal | hexadec. | octal |
|---|---|---|---|
| ` | 96 | 0x60 | 140 |
| a | 97 | 0x61 | 141 |
| b | 98 | 0x62 | 142 |
| c | 99 | 0x63 | 143 |
| d | 100 | 0x64 | 144 |
| e | 101 | 0x65 | 145 |
| f | 102 | 0x66 | 146 |
| g | 103 | 0x67 | 147 |
| h | 104 | 0x68 | 150 |
| i | 105 | 0x69 | 151 |
| j | 106 | 0x6A | 152 |
| k | 107 | 0x6B | 153 |
| l | 108 | 0x6C | 154 |
| m | 109 | 0x6D | 155 |
| n | 110 | 0x6E | 156 |
| o | 111 | 0x6F | 157 |
| p | 112 | 0x70 | 160 |
| q | 113 | 0x71 | 161 |
| r | 114 | 0x72 | 162 |
| s | 115 | 0x73 | 163 |
| t | 116 | 0x74 | 164 |
| u | 117 | 0x75 | 165 |
| v | 118 | 0x76 | 166 |
| w | 119 | 0x77 | 167 |
| x | 120 | 0x78 | 170 |
| y | 121 | 0x79 | 171 |
| z | 122 | 0x7A | 172 |
| { | 123 | 0x7B | 173 |
| 124 | 0x7C | 174 | |
| } | 125 | 0x7D | 175 |
| ~ | 126 | 0x7E | 176 |
| DEL | 127 | 0x7F | 177 |
ASCII Code, Unicode, and SEO
Although ASCII and ISO-8859 were the predominant text character standards for a long time, they are considered obsolete on the web today. The official standardization organization W3C (World Wide Web Consortium) recommends the exclusive use of UTF-8 as character encoding for all websites.
In addition to the actual texts on a web page, Unicode can also be used in meta descriptions. Unicode characters such as hooks, hearts, stars, envelopes or currency symbols can trigger unconscious impulses in the reader. For example, checkmarks and hearts generate approval, while envelopes and telephone symbols encourage contact. While this has no direct impact on search engine rankings, it increases click-through rates and leads to more visitors and customers.
In SEO-relevant keywords and keyword phrases, however, some restraint is advisable. Country-specific letters like umlauts and accents are no problem. However, unusual special characters, separating symbols, emoticons and pictograms can make keyword recognition impossible.