Difference between revisions of "Googlebot"
Ralph.ebnet (talk | contribs) (Created page with "<seo title="Googlebot" metadescription="Googlebot is Google's web crawler, which constantly scans documents from the world wide web and indexes them." /> == What is Googlebot...") |
(→Similar articles) |
||
| (11 intermediate revisions by 3 users not shown) | |||
| Line 1: | Line 1: | ||
| − | <seo title="Googlebot" metadescription="Googlebot is Google's web crawler | + | <seo title="What is Googlebot and how does it work?" metadescription="Googlebot is the name of Google's web crawler which constantly scans documents from the world wide web and makes them available for Google’s index." /> |
== What is Googlebot? == | == What is Googlebot? == | ||
| + | [[File:Googlebot.png|thumb|400px|right|alt=Googlebot|'''Figure:''' Googlebot - Author: Seobility - License: [[Creative Commons License BY-SA 4.0|CC BY-SA 4.0]]|link=https://www.seobility.net/en/wiki/images/0/02/Googlebot.png]] | ||
| − | Googlebot is the name of Google's web [[Search Engine Crawlers|crawler]], which constantly scans documents from the world wide web and makes them available for Google’s index and Google Search. It uses an automated process to continuously search for new content on the world wide web in the same way as a regular web browser: The bot sends a request to the responsible web server, which then responds accordingly. After that, it downloads a single web page that can be reached under a uniform URL and stores it in Google’s index. In this way, Google’s crawler indexes the entire internet, using distributed and scalable resources to crawl thousands of pages simultaneously. | + | Googlebot is the name of Google's web [[Search Engine Crawlers|crawler]], which constantly scans documents from the world wide web and makes them available for Google’s index and Google Search. It uses an automated process to continuously search for new content on the world wide web in the same way as a regular web browser: The bot sends a request to the responsible web server, which then responds accordingly. After that, it downloads a single web page that can be reached under a uniform URL and stores it in Google’s index. In this way, Google’s crawler [[indexing|indexes]] the entire internet, using distributed and scalable resources to crawl thousands of pages simultaneously. |
== How does Googlebot work? == | == How does Googlebot work? == | ||
| Line 14: | Line 15: | ||
== How to find out when Googlebot visited your website? == | == How to find out when Googlebot visited your website? == | ||
| + | |||
| + | The [[Google Search Console]] allows you to check when Googlebot last crawled your website. | ||
'''Step 1''' | '''Step 1''' | ||
| − | Go to Google Search Console and click on "index coverage". This opens an overview showing errors or warnings. Click on the "valid" tab to display all error-free pages. In the “details” table below, click on the row “valid” | + | Go to Google Search Console and click on "index coverage". This opens an overview showing errors or warnings. Click on the "valid" tab to display all error-free pages. In the “details” table below, click on the row “valid”. |
'''Step 2''' | '''Step 2''' | ||
| Line 26: | Line 29: | ||
== How to keep Googlebot from crawling your website? == | == How to keep Googlebot from crawling your website? == | ||
| − | There are different ways of providing or hiding certain information from web crawlers. Each crawler can be identified in the [[HTTP headers|HTTP header]] field "[[User Agent|user agent]]". For Google's web crawler,the specification is "Googlebot", which comes from the host address googlebot.com. These user agent entries are stored in the respective web server's log files and provide detailed information about who sends requests to the web server. | + | There are different ways of providing or hiding certain information from web crawlers. Each crawler can be identified in the [[HTTP headers|HTTP header]] field "[[User Agent|user agent]]". For Google's web crawler,the specification is "Googlebot", which comes from the host address googlebot.com. These user agent entries are stored in the respective web server's [[Log File|log files]] and provide detailed information about who sends requests to the web server. |
You can decide for yourself whether you want to prevent Googlebot from crawling your website or not. If you want to exclude Googlebot from your website, there are different ways to do this: | You can decide for yourself whether you want to prevent Googlebot from crawling your website or not. If you want to exclude Googlebot from your website, there are different ways to do this: | ||
| Line 36: | Line 39: | ||
== Importance for SEO == | == Importance for SEO == | ||
| − | Understanding how Googlebot works and how to influence it is particularly important for search engine optimization | + | Understanding how Googlebot works and how to influence it is particularly important for search engine optimization. For example, you can use Google Search Console to inform Googlebot about new pages on your website. Furthermore, it makes sense to create [[XML Sitemap|sitemaps]] and make them available to search engine crawlers. Sitemaps provide an overview of a website's URLs and can accelerate crawling. The most important thing, however, is to help Googlebot navigate through your website to ensure that it finds all relevant content and does not waste time browsing irrelevant pages. More information on this topic can be found in our blog post on [https://www.seobility.net/en/blog/crawl-budget-optimization/ crawl budget optimization]. |
== Related links == | == Related links == | ||
| Line 47: | Line 50: | ||
[[Category:Search Engine Optimization]] | [[Category:Search Engine Optimization]] | ||
| + | |||
| + | <html><script type="application/ld+json"> | ||
| + | { | ||
| + | "@context": "https://schema.org/", | ||
| + | "@type": "ImageObject", | ||
| + | "contentUrl": "https://www.seobility.net/en/wiki/images/0/02/Googlebot.png", | ||
| + | "license": "https://creativecommons.org/licenses/by-sa/4.0/", | ||
| + | "acquireLicensePage": "https://www.seobility.net/en/wiki/Creative_Commons_License_BY-SA_4.0" | ||
| + | } | ||
| + | </script></html> | ||
| + | |||
| + | {| class="wikitable" style="text-align:left" | ||
| + | |- | ||
| + | |'''About the author''' | ||
| + | |- | ||
| + | | [[File:Seobility S.jpg|link=|100px|left|alt=Seobility S]] The Seobility Wiki team consists of seasoned SEOs, digital marketing professionals, and business experts with combined hands-on experience in SEO, online marketing and web development. All our articles went through a multi-level editorial process to provide you with the best possible quality and truly helpful information. Learn more about <html><a href="https://www.seobility.net/en/wiki/Seobility_Wiki_Team" target="_blank">the people behind the Seobility Wiki</a></html>. | ||
| + | |} | ||
| + | |||
| + | <html><script type="application/ld+json"> | ||
| + | { | ||
| + | "@context": "https://schema.org", | ||
| + | "@type": "Article", | ||
| + | "author": { | ||
| + | "@type": "Organization", | ||
| + | "name": "Seobility", | ||
| + | "url": "https://www.seobility.net/" | ||
| + | } | ||
| + | } | ||
| + | </script></html> | ||
Latest revision as of 18:27, 4 December 2023
Contents
What is Googlebot?
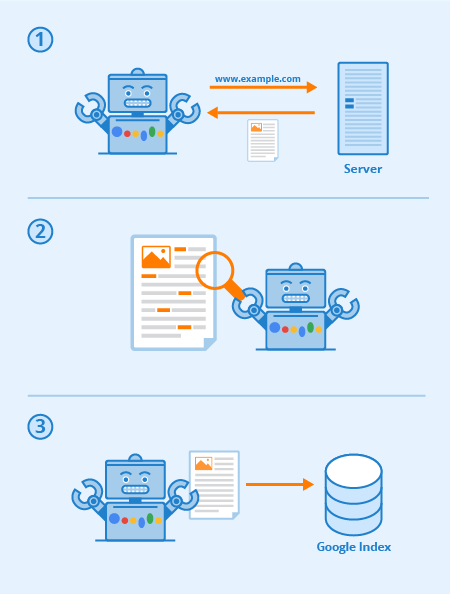
Googlebot is the name of Google's web crawler, which constantly scans documents from the world wide web and makes them available for Google’s index and Google Search. It uses an automated process to continuously search for new content on the world wide web in the same way as a regular web browser: The bot sends a request to the responsible web server, which then responds accordingly. After that, it downloads a single web page that can be reached under a uniform URL and stores it in Google’s index. In this way, Google’s crawler indexes the entire internet, using distributed and scalable resources to crawl thousands of pages simultaneously.
How does Googlebot work?
For successful search engine optimization, you have to understand the way Googlebot works. In the following, we will briefly explain this to you.
Googlebot is based on a highly developed algorithm, which is able to perform tasks autonomously and built on the concept of the world wide web (WWW). You can imagine the world wide web as a large network of web pages (nodes) and connections (hyperlinks). Each node is uniquely identified by a URL and can be reached through this web address. Hyperlinks on one page lead to further subpages or to resources on other domains. Google's bot is able to identify and analyze links (HREF links) and resources (SRC links). The algorithms can identify the most effective and fastest way for Googlebot to search the entire network.
Googlebot makes use of different crawling techniques. For example, the multi-threading method is used to simultaneously execute several crawling processes. Besides that, Google also employs web crawlers that are focussed on searching certain areas, such as crawling the world wide web by following certain types of hyperlinks.
How to find out when Googlebot visited your website?
The Google Search Console allows you to check when Googlebot last crawled your website.
Step 1
Go to Google Search Console and click on "index coverage". This opens an overview showing errors or warnings. Click on the "valid" tab to display all error-free pages. In the “details” table below, click on the row “valid”.
Step 2
You will now get a detailed overview of your web pages that are indexed by Google It shows the exact date of the last crawling for each page. Sometimes it’s possible that the latest version of a specific page has not been crawled yet. In this case, you can tell Google that the content of that page has changed and that it should be re-indexed.
How to keep Googlebot from crawling your website?
There are different ways of providing or hiding certain information from web crawlers. Each crawler can be identified in the HTTP header field "user agent". For Google's web crawler,the specification is "Googlebot", which comes from the host address googlebot.com. These user agent entries are stored in the respective web server's log files and provide detailed information about who sends requests to the web server.
You can decide for yourself whether you want to prevent Googlebot from crawling your website or not. If you want to exclude Googlebot from your website, there are different ways to do this:
- A disallow directive in your robots.txt file can exclude entire directories of your website from crawling.
- Using nofollow in the robots meta tag of a web page tells Googlebot not to follow the links on that page.
- You can also use the "nofollow" attribute for individual links to ensure that Googlebot does not follow these links (whereas all other links on that page are still crawled).
Importance for SEO
Understanding how Googlebot works and how to influence it is particularly important for search engine optimization. For example, you can use Google Search Console to inform Googlebot about new pages on your website. Furthermore, it makes sense to create sitemaps and make them available to search engine crawlers. Sitemaps provide an overview of a website's URLs and can accelerate crawling. The most important thing, however, is to help Googlebot navigate through your website to ensure that it finds all relevant content and does not waste time browsing irrelevant pages. More information on this topic can be found in our blog post on crawl budget optimization.
Related links
Similar articles
| About the author |
 |